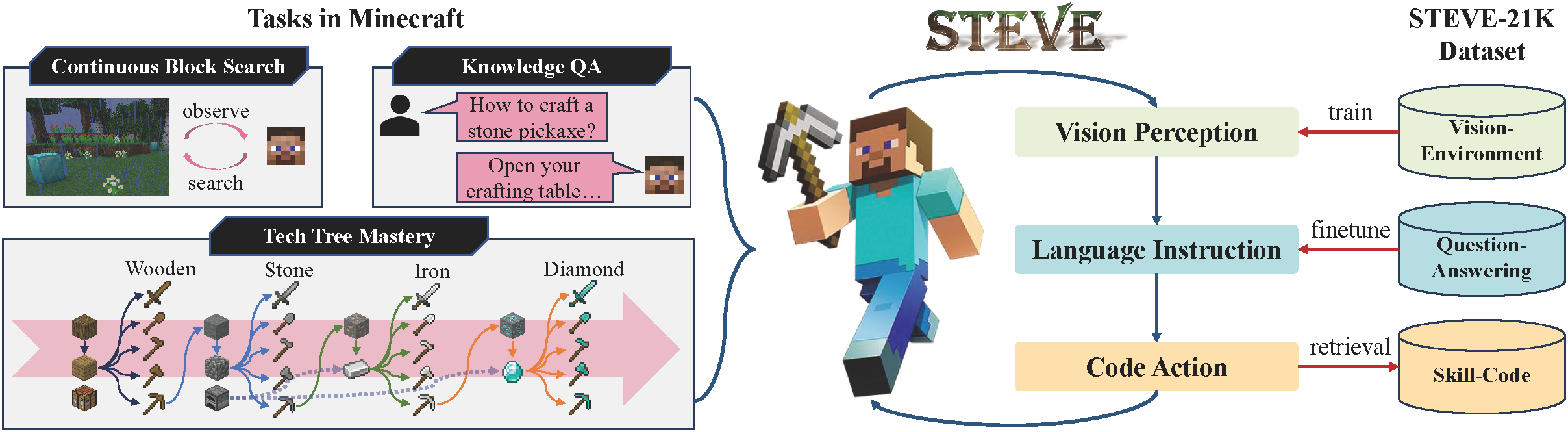
Large language models (LLMs) have achieved impressive progress on several open-world tasks. Recently, using LLMs to build embodied agents has been a hotspot. In this paper, we propose STEVE, a comprehensive and visionary embodied agent in the Minecraft virtual environment. STEVE consists of three key components: vision perception, language instruction, and code action. Vision perception involves the interpretation of visual information in the environment, which is then integrated into the LLMs component with agent state and task instruction. Language instruction is responsible for iterative reasoning and decomposing complex tasks into manageable guidelines. Code action generates executable skill actions based on retrieval in skill database, enabling the agent to interact effectively within the Minecraft environment. We also collect STEVE-21K dataset, which includes 600+ vision-environment pairs, 20K knowledge question-answering pairs, and 200+ skill-code pairs. We conduct continuous block search, knowledge question and answering, and tech tree mastery to evaluate the performance. Extensive experiments show that STEVE achieves at most 1.5x faster unlocking key tech trees and 2.5x quicker in block search tasks compared to previous state-of-the-art methods.
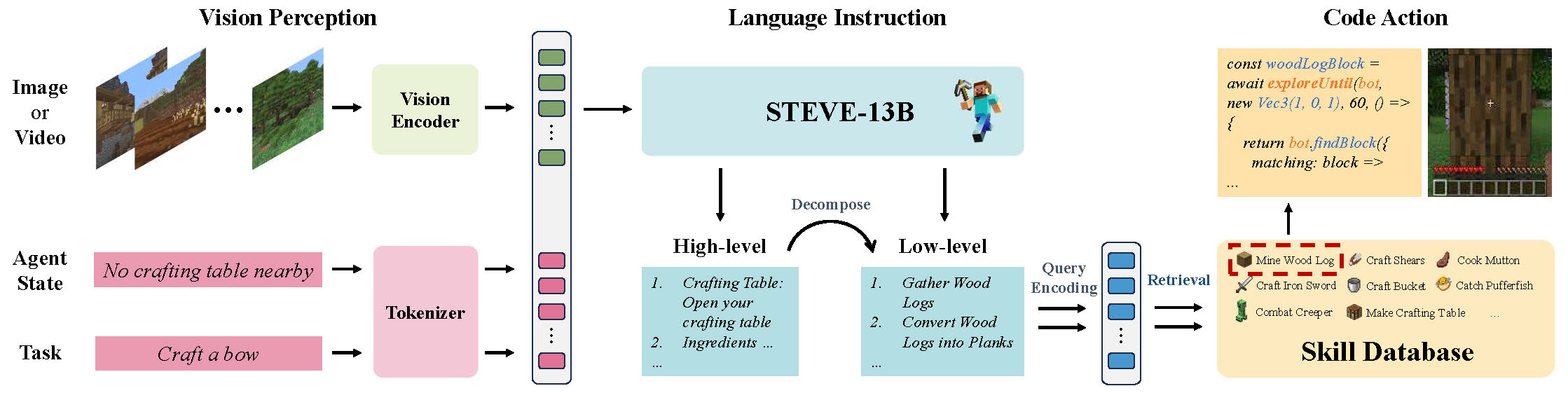
The Vision Perception part takes images or videos, encodes them into tokens, and combines them with the tokens of Agent State and Task as input. The STEVE-13B in the Language Instruction part is used for automatic reasoning and task decomposition, and it calls the Skill Database in the form of the Query to output code as action.
In the Vision-Environment section, STEVE-13B plays the game according to specified tasks defined by the human player, collecting visual information through prismarine-viewer and capturing environmental information from the screen using Ray Tracing. Note that during the collection phase, the language instruction task is also performed. We simultaneously record and save the chat flow from the reasoning and decomposition stages. In the Question-Answering section, we obtain information from the Minecraft-Wiki and Reddit forums, and use GPT-3.5 to clean the data into Single-round QA pairs. In the Skill-Code section, we use GPT-3.5 combined with the human player's code to synthesize code snippets, and then check and revise them in the game environment.
@article{zhao2023see,
title={See and Think: Embodied Agent in Virtual Environment},
author={Zhao, Zhonghan and Chai, Wenhao and Wang, Xuan and Boyi, Li and Hao, Shengyu and Cao, Shidong and Ye, Tian and Hwang, Jenq-Neng and Wang, Gaoang},
journal={arXiv preprint arXiv:2311.15209},
year={2023}
}