Abstract
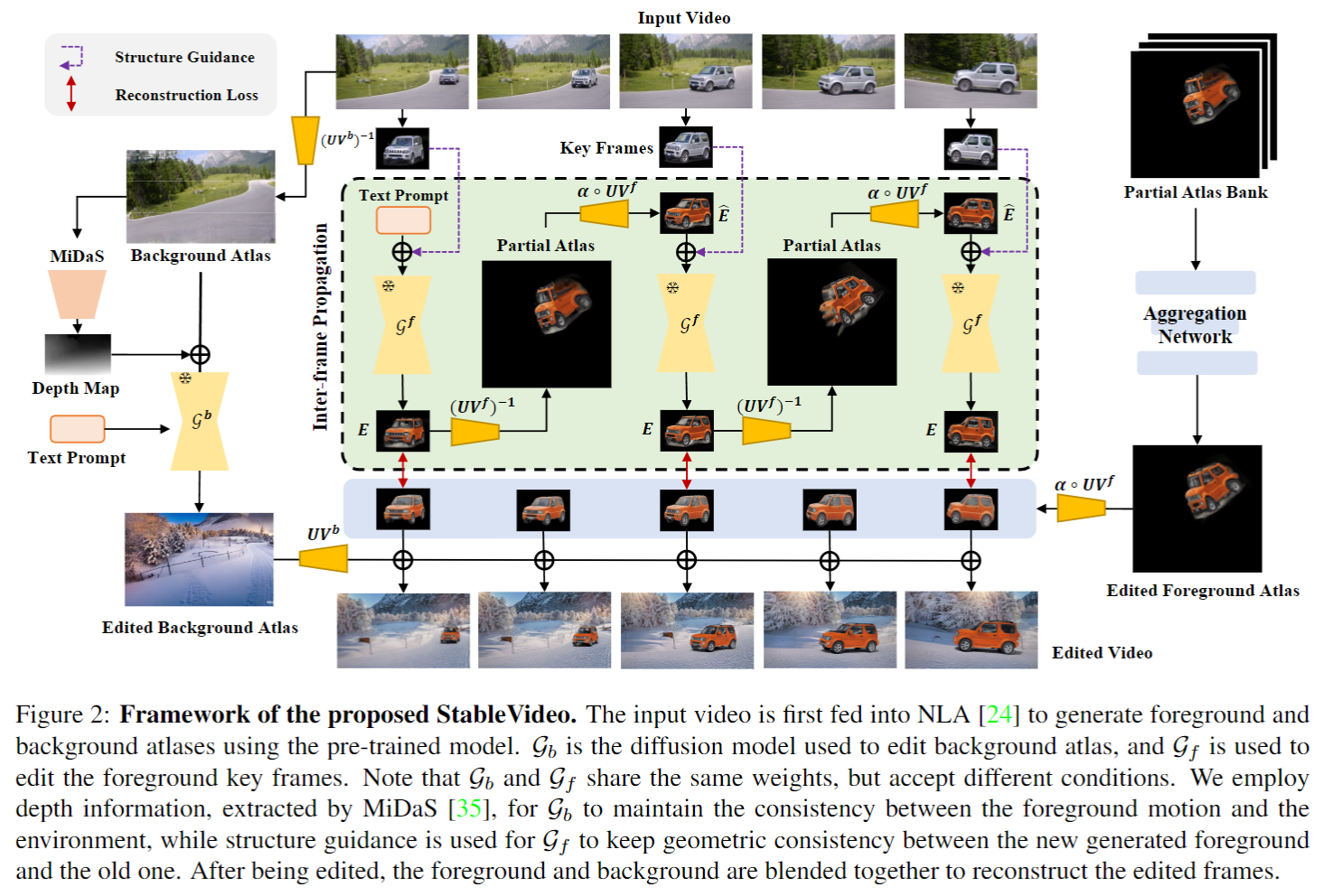
Diffusion-based methods can generate realistic images and videos, but they struggle to edit existing objects in a video while preserving their appearance over time. This prevents diffusion models from being applied to natural video editing in practical scenarios. In this paper, we tackle this problem by introducing temporal dependency to existing text-driven diffusion models, which allows them to generate consistent appearance for the edited objects. Specifically, we develop a novel inter-frame propagation mechanism for diffusion video editing, which leverages the concept of layered representations to propagate the appearance information from one frame to the next. We then build up a text-driven video editing framework based on this mechanism, namely StableVideo, which can achieve consistency-aware video editing. Extensive experiments demonstrate the strong editing capability of our approach. Compared with state-of-the-art video editing methods, our approach shows superior qualitative and quantitative results.
Overview
Bibtex