Our Research
The following presents my comprehensive research experience and areas of focus, along with a timeline highlighting the periods when I was most actively engaged in each field. The template is from here.
Large Multi-Modal Models (06/2023 - Present)
How to efficiently build and evaluate large multi-modal models?
How to involve large multi-modal models in embodied agent system?
-
Video Understanding
- Long Video with Memory MovieChat
- Gated Memory MovieChat+
- Video Detailed Captioning AuroraCap
- +RWKV LongVidRWKV
- Lecture Benchmark Video-MMLU
Generative Models (03/2023 - Present)
How to generate high-quality images, videos and 3D worlds?
How to control and evaluate the generated content?
-
Image
- Style Transfer in Fassion Diffashion
- Restoration with Diffusion Prior DTPM
- + Reinforcement Learning VersaT2I
- Science Benchmark Science-T2I
- + LMM Dream Engine
-
Video
- Video Editing with Layered Representation StableVideo
Human Pose and Motion (08/2022 - 08/2023)
How to estimate human pose and motion from images and videos?
How to generate realistic and controllable human motion?
Featured
Videos

Video-MMLU [Project Page]

EMMOE [Project Page]

AuroraCap [Project Page]

SAMURAI [Project Page]
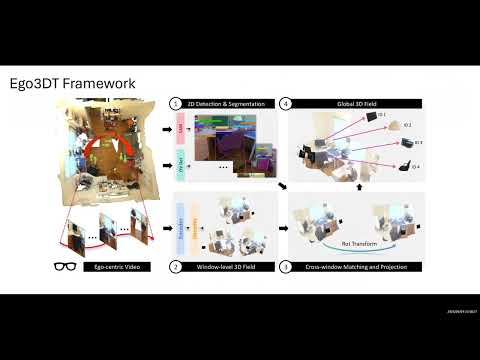
Ego3DT [Paper]
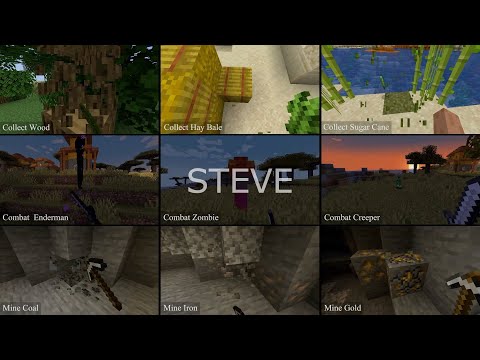
STEVE [Project Page]

StableVideo [Hugging Face Demo]

MovieChat [Project Page]
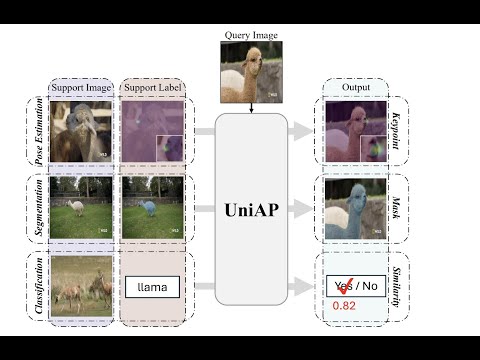
UniAP [Paper]
Organized
Workshops | Tutorials | Talks

5th International Workshop on Multimodal Video Agent
CVPR 2025, Nashville, TN
Workshop Organizer (Track 1A and 1B)

4th International Workshop on Long-form Video Understanding: Towards Multimodal AI Assistant and Copilot
CVPR 2024, Seattle, WA
Workshop Organizer (Track 1)

1st Workshop on Imageomics: Discovering Biological Knowledge from Images using AI
AAAI 2024, Vancouver, Canada
Invited Talk