Generative Models
We has been working on various tasks related to generative AI, including the creation and editing of image, video, 3D object, and 3D city.

-
StableVideo: Text-driven Consistency-aware Diffusion Video Editing
Wenhao Chai, Xun Guo‡, Gaoang Wang, Yan Lu
International Conference on Computer Vision (ICCV), 2023
Project Page | Paper | Video | Demo | Code -
Learning Diffusion Texture Priors for Image Restoration
Tian Ye, Sixiang Chen, Wenhao Chai, Zhaohu Xing, Jing Qin, Ge Lin, Lei Zhu‡
Computer Vision and Pattern Recognition (CVPR) Highlight, 2024
Paper -
DiffFashion: Reference-based Fashion Design with Structure-aware Transfer by Diffusion Models
Shidong Cao*, Wenhao Chai*, Shengyu Hao, Yanting Zhang, Hangyue Chen, Gaoang Wang‡
IEEE Transactions on Multimedia (TMM)
Paper | Code
Video Understanding
We integrate video foundation models and large language models to build a video understanding system can overcome the limitations of specific pre-defined vision tasks.
-
AuroraCap: Efficient, Performant Video Detailed Captioning and a New Benchmark
Wenhao Chai*†, Enxin Song*, Yilun Du, Chenlin Meng, Vashisht Madhavan, Omer Bar-Tal, Jenq-Neng Hwang, Saining Xie, Christopher D. Manning
International Conference on Learning Representations (ICLR), 2025
Project Page | Paper | Video | Model | Benchmark | Leaderboard | Poster | Code -
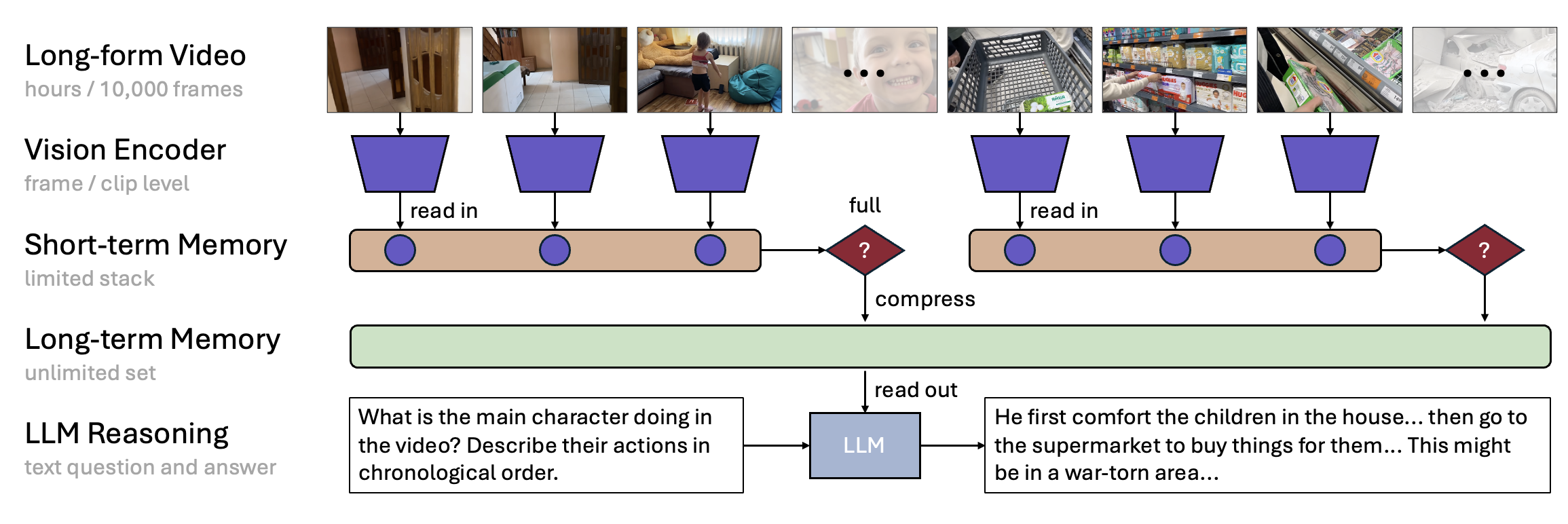
MovieChat: From Dense Token to Sparse Memory in Long Video Understanding
Enxin Song*, Wenhao Chai*†, Guanhong Wang*, Yucheng Zhang, Haoyang Zhou, Feiyang Wu, Haozhe Chi, Xun Guo, Tian Ye, Yanting Zhang, Yan Lu, Jenq-Neng Hwang, Gaoang Wang‡
Computer Vision and Pattern Recognition (CVPR), 2024
Project Page | Paper | Blog | Video | Dataset | Leaderboard | Code -
MovieChat+: Question-aware Sparse Memory for Long Video Question Answering
Enxin Song*, Wenhao Chai*†, Tian Ye, Jenq-Neng Hwang, Xi Li, Gaoang Wang‡
arXiv Preprint.
Project Page | Paper | Blog | Video | Dataset | Leaderboard | Code
Embodied Agent
Large language models (LLMs) have achieved impressive progress on several open-world tasks. Recently, using LLMs to build embodied agents has been a hotspot.
-
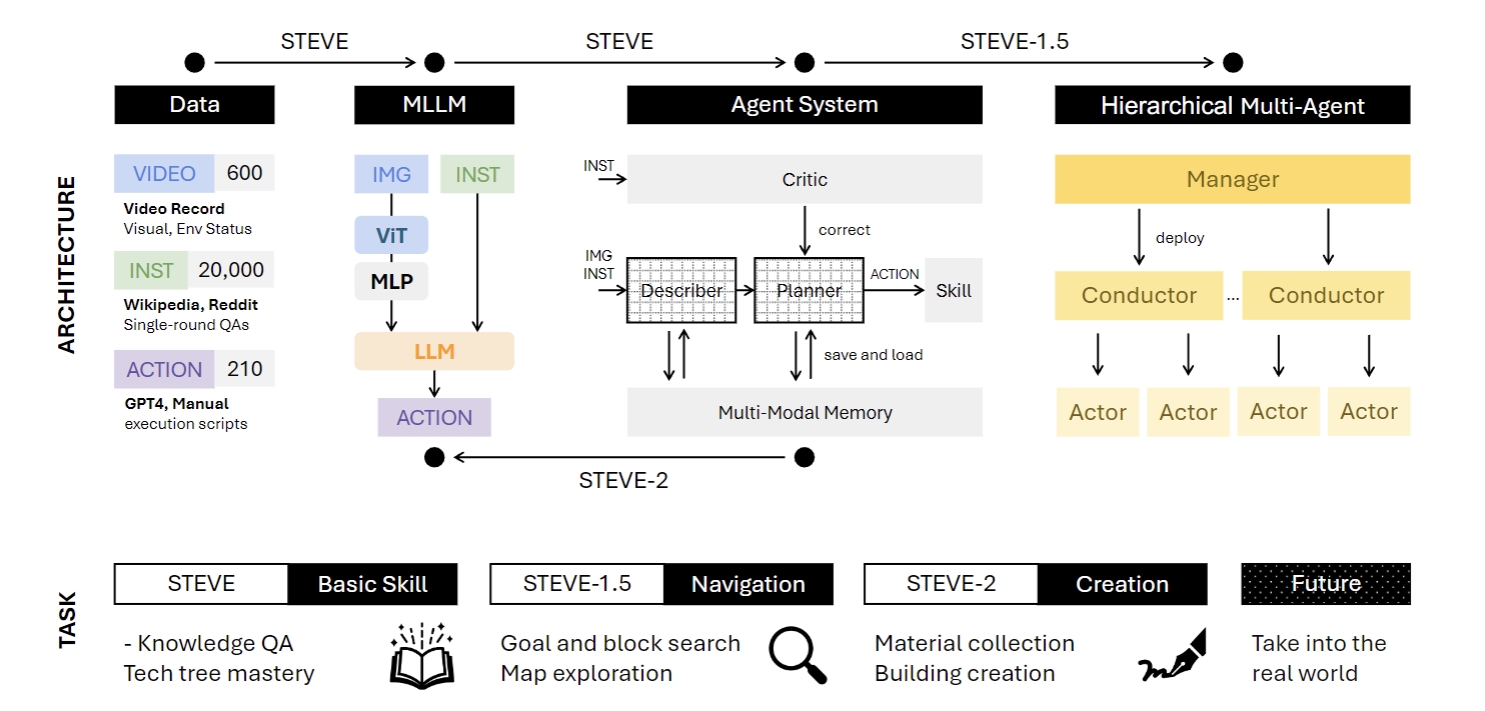
See and Think: Embodied Agent in Virtual Environment
Zhonghan Zhao*, Wenhao Chai*†, Xuan Wang*, Boyi Li, Shengyu Hao, Shidong Cao, Tian Ye, Jenq-Neng Hwang, Gaoang Wang‡
European Conference on Computer Vision (ECCV), 2024
Project Page | Paper | Dataset | Code -
Hierarchical Auto-Organizing System for Open-Ended Multi-Agent Navigation
Zhonghan Zhao*, Kewei Chen*, Dongxu Guo*, Wenhao Chai†, Tian Ye, Yanting Zhang, Gaoang Wang‡
International Conference on Learning Representations (ICLR) Workshop @ LLM Agents, 2024
Paper
Human Pose and Motion
Human pose estimation is an essential computer vision task which aims to estimate the coordinates of joints from single-frame images or videos. Our research focus on novel architecture, domain adaptation, as well as the large-scale pre-training. We also interested in animal and infent pose estimation.

-
Global Adaptation meets Local Generalization: Unsupervised Domain Adaptation for 3D Human Pose Estimation
Wenhao Chai, Zhongyu Jiang, Jenq-Neng Hwang, Gaoang Wang‡
International Conference on Computer Vision (ICCV), 2023
Paper | Code -
UniAP: Towards Universal Animal Perception in Vision via Few-shot Learning
Meiqi Sun*, Zhonghan Zhao*, Wenhao Chai*, Hanjun Luo, Shidong Cao, Yanting Zhang, Jenq-Neng Hwang, Gaoang Wang‡
Association for the Advancement of Artificial Intelligence (AAAI), 2024
Project Page | Paper | Code -
RT-Pose: A 4D Radar Tensor-based 3D Human Pose Estimation and Localization Benchmark
Yuan-Hao Ho, Jen-Hao Cheng, Sheng Yao Kuan, Zhongyu Jiang, Wenhao Chai, Hsiang-Wei Huang, Jenq-Neng Hwang, Chih-Lung Lin‡
European Conference on Computer Vision (ECCV), 2024
Paper | Dataset | Code